¿Cómo abordar el problema de la memoria a corto plazo?
Debido a las transformaciones que sufren los datos al atravesar una red neuronal recurrente, se pierde cierta información en cada paso de tiempo. Después de un tiempo, el estado de la red neuronal recurrente prácticamente no contiene rastros de las primeras entradas. Esto puede ser un problema. Imaginemos a Dory, el pez, intentando traducir una frase larga; cuando termina de leerla, no tiene ni idea de cómo empezó. Para abordar este problema, se han introducido varios tipos de células con memoria a largo plazo. Han demostrado ser tan exitosas que las células básicas ya no se utilizan mucho. Veamos primero la más popular de estas células de memoria a largo plazo: la célula LSTM.
LSTM
La celda LSTM (Long Short Term Memory) es una caja negra y se puede usar de forma muy similar a una celda básica, excepto que funcionará mucho mejor, el entrenamiento convergerá más rápido y detectará dependencias a largo plazo en los datos.
Si no miras lo que hay dentro de la caja, la celda LSTM se ve exactamente como una celda normal, excepto que su estado está dividido en dos vectores: \(h(t)\) y \(c(t)\) (“\(c\)” significa “celda”). Puedes pensar en \(h(t)\) como el estado de corto plazo y \(c(t)\) como el estado de largo plazo.
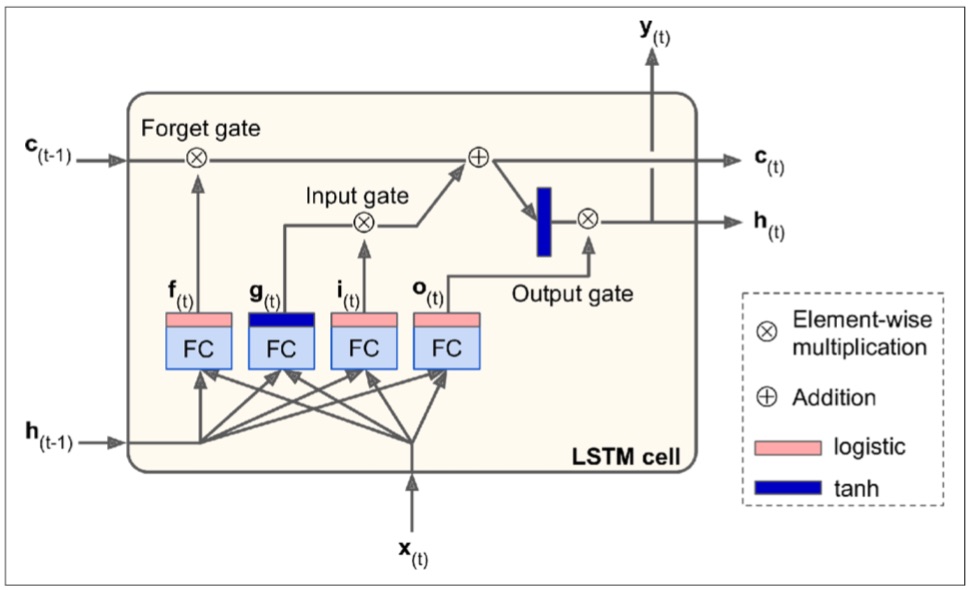
¡Ahora abramos la caja! La idea clave es que la red puede aprender qué almacenar en el estado de largo plazo, qué descartar y qué leer de él. A medida que el estado de largo plazo \(c(t–1)\) recorre la red de izquierda a derecha, se puede ver que primero pasa por una compuerta de olvido, descartando algunos recuerdos, y luego agrega algunos nuevos recuerdos a través de la operación de suma (que agrega los recuerdos que fueron seleccionados por una compuerta de entrada). El resultado \(c(t)\) se envía directamente, sin ninguna transformación adicional. Por lo tanto, en cada paso de tiempo, se descartan algunos recuerdos y se agregan algunos recuerdos. Además, después de la operación de suma, el estado de largo plazo se copia y se pasa a través de la función tanh, y luego el resultado se filtra por la compuerta de salida. Esto produce el estado de corto plazo \(h(t)\) (que es igual a la salida de la celda para este paso de tiempo, \(y(t)\). Ahora veamos de dónde provienen los nuevos recuerdos y cómo funcionan las compuertas.
En primer lugar, el vector de entrada actual \(x(t)\) y el estado de corto plazo anterior \(h(t–1)\) se introducen en cuatro capas completamente conectadas diferentes. Todas ellas cumplen una función diferente:
La capa principal es la que genera la salida \(g(t)\). Tiene la función habitual de analizar las entradas actuales \(x(t)\) y el estado anterior (de corto plazo) \(h(t–1)\). En una celda básica, no hay nada más que esta capa, y su salida va directamente a \(y(t)\) y \(h(t)\). Por el contrario, en una celda LSTM la salida de esta capa no sale directamente, sino que sus partes más importantes se almacenan en el estado de largo plazo (y el resto se descarta).
Las otras tres capas son controladores de compuertas. Dado que utilizan la función de activación logística, sus salidas van de 0 a 1. Como puede ver, sus salidas se utilizan para operaciones de multiplicación elemento por elemento, por lo que si generan 0, cierran la compuerta y si generan 1, la abren. En concreto:
— La compuerta de olvido (controlada por \(f(t)\)) controla qué partes del estado de largo plazo deben borrarse.
— La compuerta de entrada (controlada por \(i(t)\)) controla qué partes de \(g(t)\) deben agregarse al estado de largo plazo.
— Finalmente, la compuerta de salida (controlada por \(o(t)\)) controla qué partes del estado de largo plazo deben leerse y generarse en este paso de tiempo, tanto en \(h(t)\) como en \(y(t)\).
En resumen, una célula LSTM puede aprender a reconocer una entrada importante (esa es la función de la compuerta de entrada), almacenarla en el estado de largo plazo, conservarla durante el tiempo que sea necesario (esa es la función de la compuerta de olvido) y extraerla cuando sea necesario. Esto explica por qué estas células han tenido un éxito asombroso en la captura de patrones de largo plazo en series temporales, textos largos, grabaciones de audio y más.
Las siguientes ecuaciones resumen cómo calcular el estado a largo plazo de la celda, su estado a corto plazo y su salida en cada paso de tiempo para una sola instancia (las ecuaciones para un minilote completo son muy similares).
\begin{eqnarray} i_{(t)} &=& \sigma \left ( W_{xi}^T x_{(t)} + W_{hi}^T h_{(t-1)}+b_i \right)\\ f_{(t)} &=& \sigma \left ( W_{xf}^T x_{(t)} + W_{hf}^T h_{(t-1)}+b_f \right)\\ o_{(t)} &=& \sigma \left ( W_{xo}^T x_{(t)} + W_{ho}^T h_{(t-1)}+b_o \right)\\ g_{(t)} &=& tanh \left ( W_{xg}^T x_{(t)} + W_{hg}^T h_{(t-1)}+b_g \right)\\ c_{(t)} &=& f_{(t)} \otimes c_{(t-1)} + i_{(t)}\otimes g_{(t)}\\ y_{(t)}&=& h_{(t)} = o_{(t)} \otimes tanh(c_{(t)}) \end{eqnarray}En esta ecuación:
- \(W_{xi}, W_{xf}, W_{xo}, W_{xg}\) son las matrices de peso de cada una de las cuatro capas para su conexión con el vector de entrada \(x(t)\).
- \(W_{hi}, W_{hf}, W_{ho}, W_{hg}\) son las matrices de peso de cada una de las cuatro capas para su conexión con el estado de corto plazo anterior \(h(t–1)\).
- \(b_i, b_f, b_o , b_g\) son los términos de sesgo para cada una de las cuatro capas.
- \(tanh(x) = \frac{e^x-e^{-x}}{e^x + e^{-x}}\)
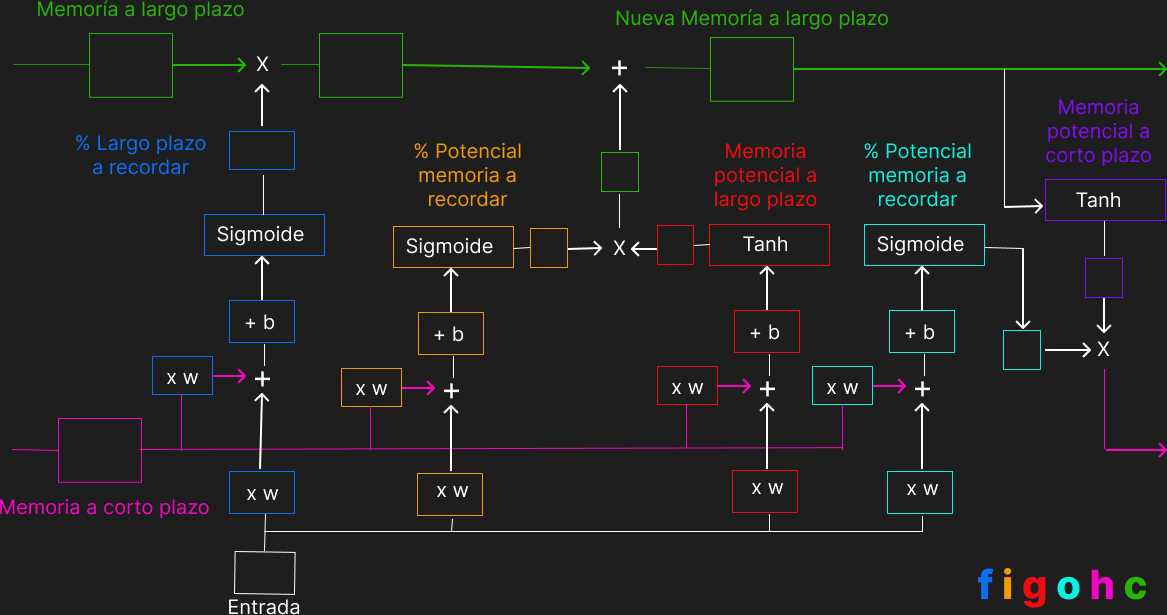
Otra ejemplificación de este tipo de celda es la siguiente, donde los cuadrados vacíos son los valores concretos, \(w,b\) son pesos y sesgo, respectivamente. En la esquina inferior derecha se ven las letras de colores que corresponden a las ecuaciones antes mencionadas. Por otro lado recordemos que la función sigmoide tiene como imagen a \((0,1)\) lo cual se puede interpretar como una proporción o probabilidad. En forma resumida una celda LSTM divide la forma de procesar el pasado en largo plazo (Long Term) color verde y corto plazo (Short Term) color rosa.
Variantes
LSTM bidireccional
Un LSTM bidireccional como se usa en HYBRID SPEECH RECOGNITION WITH DEEP BIDIRECTIONAL LSTM consta de dos LSTM que se ejecutan en paralelo: uno en la secuencia de entrada y el otro en el reverso de la secuencia de entrada. En cada paso de tiempo, el estado oculto del LSTM bidireccional es la concatenación de los estados ocultos hacia adelante y hacia atrás. Esta configuración permite que el estado oculto capture información pasada y futura.
LSTM multicapa
En arquitecturas LSTM multicapa, el estado oculto de una unidad LSTM en la capa \(l\) se utiliza como entrada para la unidad LSTM en la capa \(l+1\) en el mismo paso de tiempo, como lo hacen en Sequence to Sequence Learning with Neural Networks y HYBRID SPEECH RECOGNITION WITH DEEP BIDIRECTIONAL LSTM . Aquí, la idea es dejar que las capas superiores capturen dependencias a más largo plazo de la secuencia de entrada.
Referencias